Wise-Agent Architecture
Disclaimer: This page is under construction and continuously updated.
General Architecture
WiseAgent is a multi-agent intelligent framework designed for distributed, asynchronous communication. It is capable of connecting to any LLM model or inference system that supports the OpenAI API, enabling the use of multiple different models within the same configuration. One of the key features of WiseAgent is its cloud readiness and distributed nature, allowing for the deployment of different components in separate pods, while also being able to run everything in a single process for simpler use cases.
The following image provides a high-level overview of the architecture and flow:
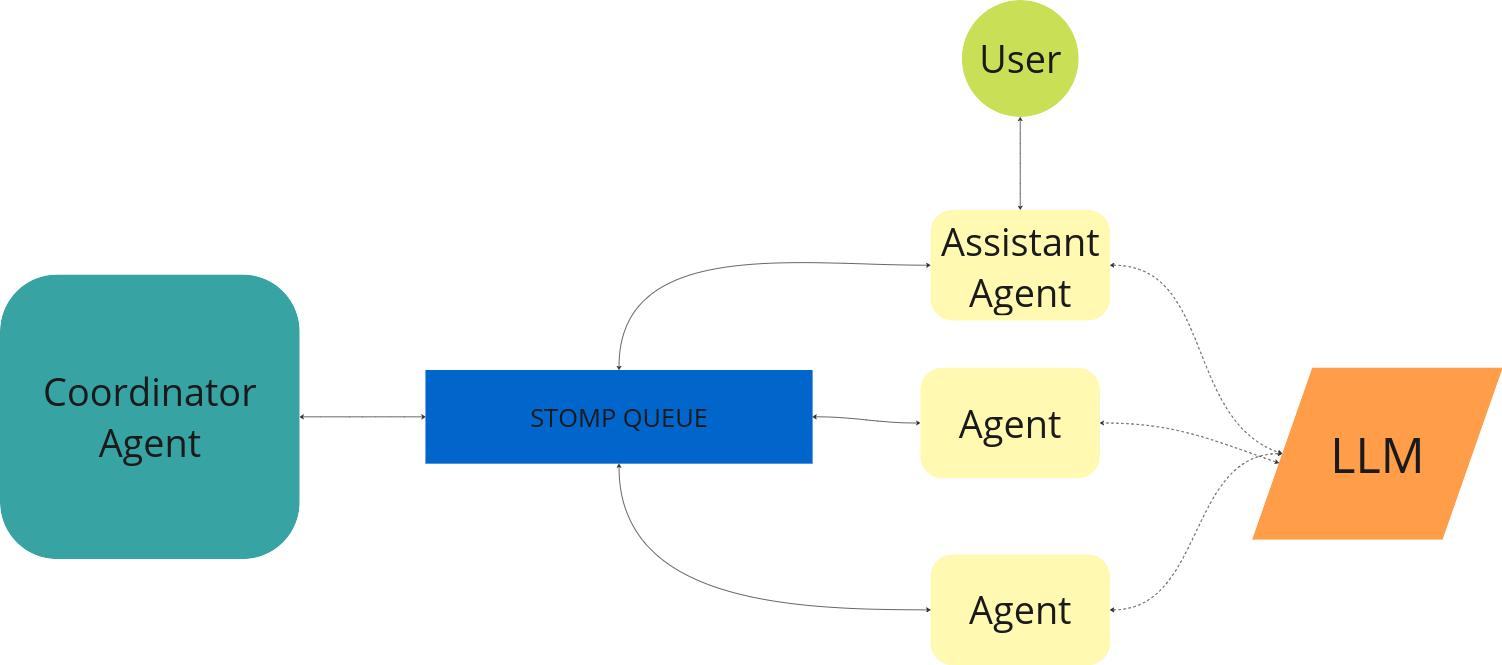
TODO
Wise-Agent Components
-
WiseAgents: These are the core components where the actual processing occurs. Each WiseAgent MUST be capable of communicating via the STOMP protocol. It MUST be able to process an input message in the WiseAgentMessage format and produce a WiseAgentMessage as output. An agent MAY have perceiving capabilities (such as monitoring changes in files, reacting to events, etc.). Additionally, it MAY integrate with an LLM through the OpenAI API, supporting tools (both external APIs and other agents acting as tools). A WiseAgent MAY be capable of taking actions, such as executing tools or APIs. The framework currently supports features like GraphRAG and tool calls, and it can be extended to support additional functionalities. Specialized implementations of WiseAgents can handle orchestration or triage of inputs. In essence, every component of the WiseAgent framework, except for the registry and context, is an agent with specific capabilities.
-
WiseAgentMessage: This is the format used for communication between agents. There are generally two types of communication:
- The main content is carried in the WiseAgentMessage payload as natural language.
-
The WiseAgentMessage is used solely for ACK/NACK purposes, with the actual content being part of the shared memory within a specific execution context.
-
Communication Protocol: The WiseAgent framework is designed to enable asynchronous communication between agents. The current implementation uses the STOMP 1.0 protocol, which is supported by various message queue systems such as ArtemisMQ and RabbitMQ.
-
LLM Integration: A WiseAgent MAY utilize an LLM to process requests and generate responses. This integration is facilitated through the standard OpenAI API, which supports any model or inference system that provides OpenAI API access. The framework manages the memory of previous message tokens that form the context for each LLM request, allowing these contexts to be shared between agents participating in the same execution context.
-
Agents' Registry: When an agent is created and deployed, it registers itself with the Agents' Registry, providing a name and a detailed natural language description (with possible added metadata) of its capabilities. These descriptions are used by the coordinator to select the appropriate agents to solve a specific problem or to address a phase of the problem solution.
-
Agents' Execution Context: Each session or query lifecycle is tracked within an execution context. This context stores shared information such as available and executed tools, the current phase of execution, etc. It also serves as the shared memory where agents collaborate to keep track of LLM interactions. By managing shared memory at the agents' level instead of the LLM integration level, the WiseAgent framework allows different agents—potentially using different LLM models—to share contextual information.
-
Agents' Coordinator: The coordinator is responsible for organizing the work among agents. It determines which agents are needed to provide a solution, the order in which they should execute, and how they should cooperate to achieve the final result. The framework provides different coordinator implementations:
- SequentialCoordinator: Processes the request by routing it sequentially to various agents. Partial answers from each agent can be utilized by subsequent agents in the sequence, culminating in a final response to the client.
-
PhasedCoordinatorWiseAgent: This coordinator groups agents into different phases and then executes each phase in parallel. The results from each agent enrich the shared context and can be selectively used by the coordinator or any other agent in subsequent phases. Agents within the same phase cannot depend on each other. Note: An agent defined to run in a specific phase can act as a SequentialCoordinator for complex compositions. Currently, it is not possible to compose another PhasedCoordinatorWiseAgent within a phase.
-
Perceptions' Triage Agent: This is essentially another coordinator, specifically tasked with collecting, filtering, and aggregating inputs from agents with perceiving capabilities. The output from the triage process is a natural language question or problem description, complete with all relevant data and details. This output serves as the input for the Agents' Coordinator to produce a final answer or create an action plan.
-
RAG Agents: Retrieving additional relevant information is a key capability of a multi-agent system. The WiseAgent framework provides advanced RAG (Retrieval-Augmented Generation) and GraphRAG agents that can be used or extended. For more details, see RAG Architecture.
LLM Integration
As mentioned earlier, LLM integration is achieved through a client-side implementation of the OpenAI API. The responsibility for tracking messages exchanged with the LLM lies with the agent, not the LLM integration layer. This design choice makes the WiseAgent framework agnostic to the specific LLM model used, as long as the model and inference system support the OpenAI API. This approach allows different agents to potentially use different models while sharing a unified memory. For more information, see RAG Architecture.
Distributed architecture
As said above, wise-agents has been designed as a fully distributable cloud-ready architecture. For this reason, each agent can ideally run in a different pod and communicate with others through asynchronous communication based on STOMP protocol.
All agents use a shared memory to access the Agent's Registry and Agent's Context. This is done by a shared Redis server, which can be configured with a file named registry_config.yaml from the current directory. If not found in current directory it is loaded from ~/.wise-agents/registry_config.yaml. The file looks like:
use_redis: true #if falseredis not used and all agents need to be in the same process
redis_host: localhost
redis_port: 6379
redis_db: wise-agents
redis_ssl : false #ssl connection. if it's true you need to set also all the following parameters
redis_username: default
redis_password: secret
redis_ssl_certfile: "./redis_user.crt"
redis_ssl_keyfile: "./redis_user_private.key"
redis_ssl_ca_certs: "./redis_ca.pem"
Note: To configure SSL you need Redis enterprise
For more information about redis connection please refer to official redis documentation